Welcome back, SFML enthusiasts! This article is a follow-up to my previous deep dive into my fork of SFML.
If you want to know how I managed to draw 500k
sf::Sprite objects at over ~60FPS compared to upstream’s
~3FPS, keep on reading!
Here, we’ll explore two new significant features in my fork:
A batching system that works with every SFML drawable
Simplification of core SFML APIs to aggregates, including
sf::Transformable
These enhancements aim to improve performance and simplify usage for developers working with SFML.
drawable batching
Let’s talk about a long-standing problem with upstream SFML: it has always issued one draw call per drawable object (sometimes even two1).
That means that drawing 1000 sf::Sprite objects will
bombard the GPU with 1000 separate draw calls.
This approach doesn’t scale well, forcing users to resort to lower-level primitives for performance-critical features like particle systems or games with a large number of active entities.
It’s no surprise that batching in SFML has been on the community wish list for ages2. There have been a few solid attempts to implement it, but they never made it into the main codebase. Two notable pull requests (PR #1802 and PR #2166) showcase these efforts. In my opinion, the first one was going in the right direction, while the second one is a bit too complicated.
the texture dilemma
The main stumbling block in previous attempts was dealing with drawables sporting different textures. Those proposed batching systems tried to solve the issue by sorting the drawables by texture, which would mess up the original drawing order and complicate their internals.
I decided to work around this issue rather than trying to solve it directly.
Users can now easily create a texture atlas on the fly by adding
textures to the atlas one by one, and they will be internally packed3. This solution significantly
simplifies the design of a batching system. Enter the sf::TextureAtlas
class:
// Create a 1024x1024 empty texture atlas
sf::TextureAtlas atlas{sf::Texture::create({1024u, 1024u}).value()};
// Load an image of a cat from file
const auto catImage = sf::Image::loadFromFile("cat.png").value();
// Add the cat image to the texture atlas
// The returned rectangle is where the image lives in the atlas
const sf::FloatRect catRect = atlas.add(catImage).value();
// Fonts can also be associated with a texture atlas
// Glyphs are dynamically loaded on demand into the atlas
const auto fontTuffy = sf::Font::openFromFile("tuffy.ttf", &atlas).value();
// Example: drawing a sprite associated with a texture atlas
sf::Sprite catSprite{catRect};
someRenderTarget.draw(catSprite, atlas.getTexture());batches are drawable
I realized that the most natural API for a batching system should
draw an arbitrary number of drawables under the same
sf::RenderStates, which notably stores a single
sf::Texture*. While this would be a significant limitation
if sf::TextureAtlas didn’t exist, it’s now not a big
deal.
That observation also implies that drawable batches are “normal” drawables themselves!
In my fork, I have implemented a new drawable: sf::DrawableBatch4. It’s a fully-working batching
system that supports any SFML drawable (and also allows users to batch
arbitrary vertices).
sf::DrawableBatch batch;
// ...
batch.clear();
// ...
batch.add(someSprite);
batch.add(someText);
batch.add(someCircleShape);
// ...
someRenderTarget.draw(batch,
sf::RenderStates{.texture = &atlas.getTexture()});The usage is straightforward: add your drawables to the batch, then
draw it all at once on any sf::RenderTarget with your
chosen sf::RenderStates. This approach draws everything in
a single draw call, resulting in massive performance gains. Implementing
something like a particle system with sf::Sprite is now
completely reasonable.
Conceptually, sf::DrawableBatch is very simple:
Adding a drawable results in all of its vertices being added to an internal buffer, pre-transformed on the CPU based on the drawable’s
sf::Transform.Under the hood,
sf::RenderTargetuses indexed drawing viaglDrawElements, making it straightforward to batch different types of primitives together (e.g., triangle strips, triangle fans, etc.).That’s pretty much it – it just works™.
Furthermore, sf::DrawableBatch is a
sf::Transformable. This means that a bunch of drawables
could be “cached” into a sf::DrawableBatch and then
rendered with different transforms multiple times. This feature is
particularly useful for drawables that require significant computation
to initially generate vertices.
streaming data to the GPU
Of course, the previous explanation glossed over some crucial details. One of the most pressing questions is: how do we optimally stream a massive amount of vertices to the GPU in OpenGL?
To be honest, I don’t have a definitive answer.
However, after experimenting with various techniques, I’ve narrowed it down to two particularly effective methods.
opengl es and webgl
For OpenGL ES platforms (e.g. mobile devices, or WebGL via
Emscripten), I found that a
straightforward “naive” call to glBufferData with
GL_STREAM_DATA yielded the best results. Surprisingly,
more sophisticated approaches like double VBO buffering or buffer
orphaning didn’t provide any noticeable performance gains in my
tests.
That said, I might have overlooked something, so feel free to take a
crack at optimizing that code yourself – you’ll find it in
RenderTarget.cpp, specifically in the
streamToGPU function.
desktop platforms
On desktop platforms, we can leverage a more powerful technique: persistent buffer mapping. This approach allows us to create a buffer on the GPU and map it once, keeping around a pointer that we can write to directly. In essence, we get as close as possible to producing the pre-transformed vertices right in the GPU buffer.
However, the implementation is far from trivial:
I had to create a
sf::GLPersistentBufferclass, essentially a GPU-sidestd::vectorthat dynamically resizes based on usage.Explicit synchronization was necessary to prevent data races between the CPU and GPU. To handle this, I implemented a
sf::GLSyncGuardRAII guard class.
My synchronization strategy is rudimentary but seems to work:
Always utilize the entire buffer: clear it before adding drawables to the batch, fill it with vertices, then draw it all at once
Lock the entire persistent buffer before the
glDrawElementscallUnlock it immediately after
I’ll admit, there was a lot of trial and error involved here. My familiarity with the OpenGL API was limited, so there might be more efficient ways to achieve the same result. If you’ve got ideas for improvement, I’m all ears!
performance results
Despite the potential for optimization, both techniques deliver impressive results. On my high-end system5, I observed the following:
| Scenario | Batching | FPS |
|---|---|---|
500k sf::Sprite objects |
no batching | ~3 |
250k sf::CircleShape objects |
no batching | ~2 |
500k sf::Sprite objects |
CPU buffer batching | ~52 |
250k sf::CircleShape objects |
CPU buffer batching | ~35 |
500k sf::Sprite objects |
GPU persistent buffer batching | ~68 |
250k sf::CircleShape objects |
GPU persistent buffer batching | ~51 |
Note: These aren’t rigorous benchmarks, but the performance improvements are evident.
You can play around with the benchmark online – I am very curious to hear if you get similar performance improvements, but keep in mind that the WebGL version of the benchmark is inherently slower than the desktop one.
future optimizations?
The current bottleneck lies in performing all the vertex pre-transformation on the CPU. In theory, I could offload this to the GPU, but that introduces a whole new level of complexity that might not be worth the potential gains, given the already impressive results. Here’s why I’m hesitant:
I’d need to pass a transform matrix per drawable to the shader, which can be done in several ways (e.g. SSBOs).
Ensuring compatibility with OpenGL ES and WebGL would further complicate the implementation.
There’s no guarantee it would be significantly faster. The overhead from sending large amounts of extra data to the GPU could be substantial.
For now, I’ve decided to stick with the current implementation. But I might give GPU-side transformation a shot in the future.
core API simplification
I’ve made significant changes to core SFML APIs, particularly
sf::Transformable, aiming to simplify usage, improve
performance, and leverage modern C++ features.
farewell to polymorphism
In upstream SFML, every drawable derives polymorphically from
sf::Drawable and sf::Transformable. I’ve taken
a different approach:
Completely eliminated
sf::DrawableChanged
sf::Transformableto be non-polymorphic
Even in upstream SFML, sf::Transformable didn’t expose
any virtual member functions except for the destructor, so
there was little point in polymorphism there.
transforming
sf::Transformable
sf::Transformable is responsible for storing the
position, origin, rotation, and
scale of a drawable object. In upstream SFML, it also caches
and stores the transform and inverse transform
matrices of the drawable, plus some “dirty” boolean flags that keep
track of whether those transform matrices must be recalculated.
In order to “cache” the transforms, the API exposed by
sf::Transformable is OOP-like (based on getters and
setters):
// same as `sprite.setPosition(sprite.getPosition() + velocity))`
sprite.move(velocity);
// same as `sprite.setRotation(sprite.getRotation() + sf::radians(torque)))`
sprite.rotate(sf::radians(torque));
if ((sprite.getPosition().x > windowSize.x && velocity.x > 0.f) ||
(sprite.getPosition().x < 0.f && velocity.x < 0.f))
velocity.x = -velocity.x;The upstream API, while functional, has several drawbacks:
Simple operations like moving or rotating a sprite require one or more function calls.
The syntax is noisy and hard to read compared to simple vector operations.
Function call overhead can accumulate in unoptimized (e.g., debug) builds.
In my fork, sf::Transformable
is now an aggregate. The caching is gone, the getters and setters
are gone, and the new API is straightforward and intuitive:
sprite.position += velocity;
sprite.rotation += sf::radians(torque);
if ((sprite.position.x > windowSize.x && velocity.x > 0.f) ||
(sprite.position.x < 0.f && velocity.x < 0.f))
velocity.x = -velocity.x;performance implications
You might think that removing the caching of transform matrices is a performance loss, as they now need to be computed on demand. However, it’s actually a performance win for several reasons:
Reduced Size: The size of
sf::Transformabledecreased considerably (from 168B to 28B), improving CPU cache utilization.No Dirty Flags: Operations mutating position, origin, rotation, and scale no longer need to set dirty flags.
Fewer Function Calls: Without wrapper functions, debug performance improves, and the compiler has more optimization opportunities in release mode.
Optimized for Dynamic Scenes: In games, most entities change every frame, meaning the transform would have to be recomputed anyway. Now there are fewer branches when doing so.
Additionally, profiling with Intel VTune had detected
std::sin and std::cos as a bottleneck in the
sf::Transformable::getTransform function. I’ve replaced
those with a lookup table containing 65,536 entries, whose precision is
acceptable and speedup significant.
size matters
The size reduction of sf::Transformable is significant.
Let’s break it down:
| Type | Upstream SFML | My fork |
|---|---|---|
sf::Transform |
64B, non-aggregate | 24B, aggregate |
sf::Transformable |
128B, non-aggregate | 28B, aggregate |
sf::Sprite |
280B, non-aggregate | 48B, non-aggregate |
Note: Sizes may vary slightly depending on the system and compiler.
This size reduction has a significant impact on memory usage. In
upstream SFML, storing 100k sf::Sprite objects would take
around ~26MB. With the optimizations in my fork, this memory footprint
is drastically reduced.
The size improvements are inspired by PR #3026 by L0laapk3, which hardcoded the
bottom row of the transformation matrix to {0, 0, 1}. It
was ultimately rejected due to unconvincing benchmarks and because it
was deemed out of scope for SFML 3.x. In my fork, I’ve taken this
concept much further by storing
only the six floats required for every 2D transformation rather than a
float[16] matrix.
the power of aggregates
The use of C++20 designated initializers makes it extremely convenient to initialize aggregate types. The following are all now aggregates:
sf::BlendModesf::Colorsf::RenderStatessf::Transformsf::Transformablesf::Vertexsf::Viewsf::Rect<T>sf::Vector2<T>sf::Vector3<T>sf::VideoMode
For other types, I’ve created small
aggregate “settings” structs that are now taken during construction.
Here’s a comparison of how sf::Text is initialized:
// My fork
sf::Text hudText(font,
{.position = {5.0f, 5.0f},
.characterSize = 14,
.fillColor = sf::Color::White,
.outlineColor = sf::Color::Black,
.outlineThickness = 2.0f});
// Upstream
sf::Text hudText(font);
hudText.setCharacterSize(14);
hudText.setFillColor(sf::Color::White);
hudText.setOutlineColor(sf::Color::Black);
hudText.setOutlineThickness(2.0f);
hudText.setPosition({5.0f, 5.0f});The aggregate-based initialization in my fork not only simplifies the
code but also allows the use of const where
appropriate.
visual impact
To illustrate the real-world impact of these changes, I’ve prepared a
visual comparison of the Tennis.cpp example between
upstream SFML and my fork:
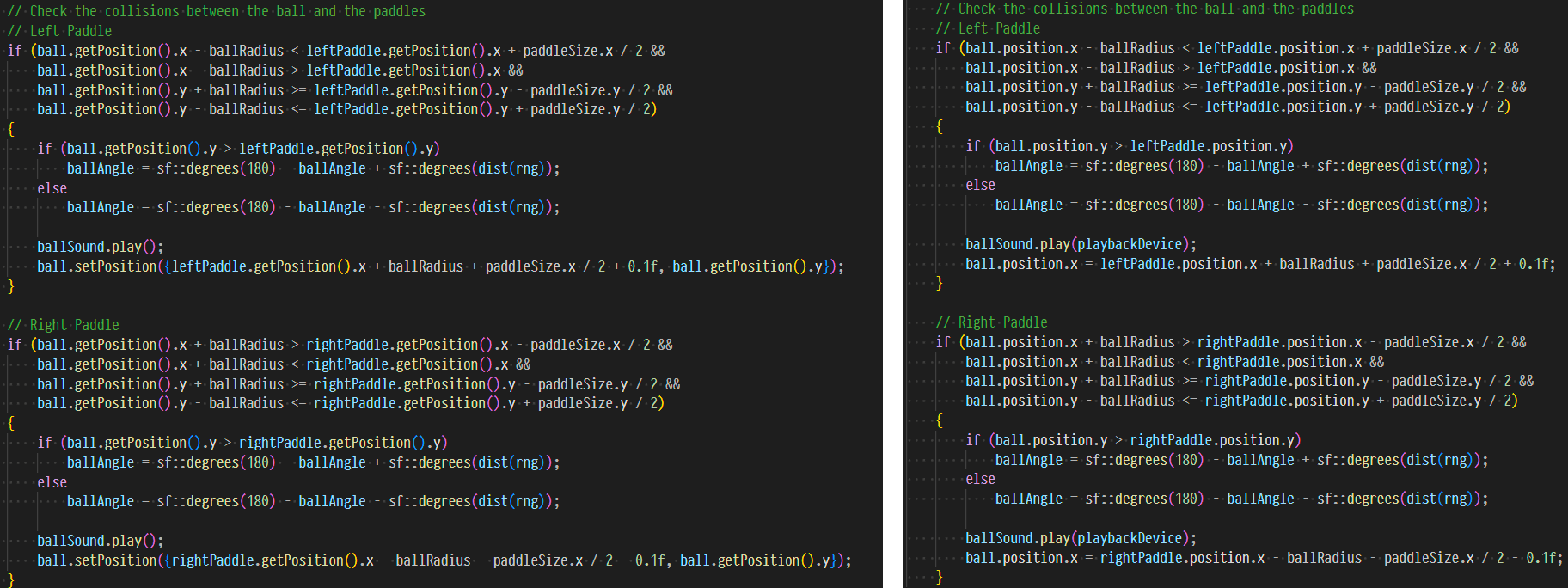
As you can see, my version is more concise and easier to read, while still maintaining all the functionality of the original.
try it out
You can now experience many SFML examples[^examples] directly in your browser:
- Visit
vittorioromeo/VRSFML_HTML5_Examplesto explore these demos.
If you want to use my fork of SFML yourself, the source code is available here.
- The fork is still a work-in-progress and experimental project, but it is mature enough to build something with it. The documentation is lackluster, but feel free to reach out and I will directly help you out get started!
By the way, the name of the fork is still undecided – VRSFML is a placeholder which will change soon.
shameless self-promotion
I offer training, mentoring, and consulting services. If you are interested, check out romeo.training, alternatively you can reach out at
mail (at) vittorioromeo (dot) comor on Twitter.My book “Embracing Modern C++ Safely” is available from all major resellers.
- For more information, read this interview: “Why 4 Bloomberg engineers wrote another C++ book”
If you enjoy fast-paced open-source arcade games with user-created content, check out Open Hexagon, my VRSFML-powered game available on Steam and on itch.io.
- Open Hexagon is a community-driven spiritual successor to Terry Cavanagh’s critically acclaimed Super Hexagon.
Shape and text drawables issue two separate draw calls if they have a visible outline.↩︎
The
stb_rect_packlibrary is used under the hood.↩︎At the moment, I actually have two different batch types:
sf::CPUDrawableBatchwhich stores vertex data in a CPU buffer, andsf::PersistentGPUDrawableBatchwhich stores vertex in a persistently mapped GPU buffer. The latter is not supported on OpenGL ES, but it’s faster.↩︎i9 13900k, RTX 4090↩︎