One of the best features of futures (or promises, depending on your language background) is the ability of composing them through asynchronous continuations. Example:
// pseudocode
auto f = when_all([]{ return http_get("cat.com/nicecat.png"); },
[]{ return http_get("dog.com/doggo.png"); })
.then([](auto p0, auto p1)
{
send_email("mail@grandma.com", combine(p0, p1));
});
f.execute(some_scheduler);In the above pseudocode snippet, the http_get requests
can happen in parallel (depending on how the scheduler
works - you can imagine it’s a thread pool). As soon as both
requests are done, the final lambda is automatically invoked with both
payloads.
I find this really cool because it allows developers to define
directed acyclic graphs of asynchronous/parallel computations
with a very clear and readable syntax. This is why the currently
crippled std::future is evolving into something more
powerful that supports .then and when_all:
these facilities are part of N4538: “Extensions for
concurrency” - Anthony Williams introduced them excellently in his
ACCU 2016 “Concurrency,
Parallelism and Coroutines” talk.
hidden (?) overhead
Let’s look more closely at the signature of std::experimental::future::then:
template <class F>
auto std::experimental::future<T>::then(F&& func)
-> std::experimental::future<
std::result_of_t<std::decay_t<F>(std::experimental::future<T>)>
>;As you can see, the return type is well-defined, and it is another
std::experimental::future. This means that the continuation
is type erased into a new future. This is how a possible
implementation of then might look like:
template <class T, class F>
auto then(std::experimental::future<T>& parent, std::launch policy, F&& f)
-> std::experimental::future<
std::result_of_t<F(std::experimental::future<T>&)>
>
{
return std::async(std::launch::async, [
parent = std::move(parent),
f = std::forward<F>(f)
]
{
parent.wait();
return std::forward<F>(f)(parent);
});
}Hmm… std::async, type erasure… this means that there
might be potential allocations! Let’s attempt to roughly measure their
overhead. I created five
.cpp files where I used boost::async and
boost::future to create a chain of .then
continuations, starting with zero continuations and ending with four.
Example:
// zero continuations
int main()
{
return boost::async([]{ return 123; }).get();
}
// one continuations
int main()
{
return boost::async([] { return 123; })
.then([](auto x) { return x.get() + 1; })
.get();
}
// ...
// four continuations
int main()
{
return boost::async([] { return 123; })
.then([](auto x) { return x.get() + 1; })
.then([](auto x) { return x.get() + 1; })
.then([](auto x) { return x.get() + 1; })
.then([](auto x) { return x.get() + 1; })
.get();
}I then compiled every file with…
# g++ 7.1
g++ -std=c++1z -Ofast -DNDEBUG -S…and counted the lines of stripped generated assembly. These are the results:
| Continuations | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| Lines of asm | 10111 | 10949 | 11581 | 12178 | 12843 |
Plotted:
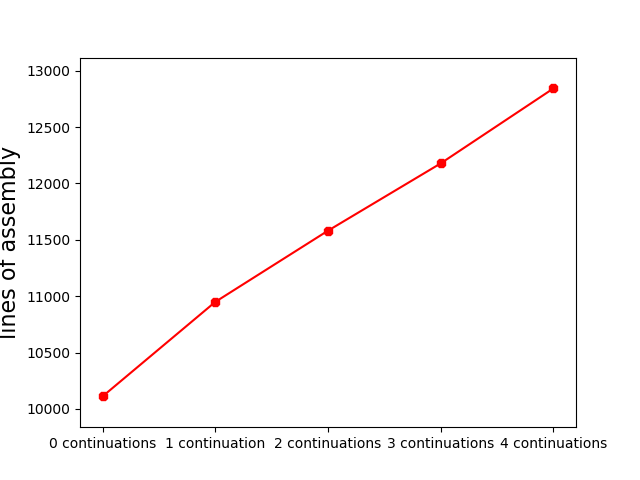
This shows a very approximate increment of 500-800 lines of assembly
per .then continuation. I know what you’re thinking…
This is a terrible benchmark that doesn’t prove anything!
…and I almost completely agree. What I wanted to show is that due to
the use of boost::async, type erasure, and
potential allocations, the compiler is unable to “compress” the
continuations into a single chain of operations and instead keeps every
future instance allocated somewhere in memory.
This might be desirable, depending on your use case - the
Callable invoked by .then does indeed take a
future as an argument instead of the result of
.get(). But this might also be undesirable - in this
situation the compiler can see the entire chain of .then
calls, and could ideally allocate once for all of them.
Additionally, even if the overhead of allocations and scheduling is usually small compared to IO operations, it might add up if a program extensively uses asynchronous continuations.
an alternative design
I’d like to show an alternative design that doesn’t require
any allocation whatsoever and still enables users to
build up asynchronous computation chains using facilities such as
when_all and .then.
What’s the secret?
Avoiding type erasure and allowing the type of the
Callable objects passed to the continuations to persist.
This is what we’re going to implement in this article:
int main()
{
auto f = initiate([]{ return 1; })
.then([](int x){ return x + 1; })
.then([](int x){ return x + 1; });
f.execute(/* some scheduler */);
}How many lines of generated assembly with a purely sequential and synchronous scheduler?
struct synchronous_scheduler
{
template <typename F>
decltype(auto) operator()(F&& f) const
{
return f();
}
};2! The compiler is able to inline everything.
How many lines of generated assembly with a scheduler that simply
calls std::async?
struct asynchronous_scheduler
{
template <typename F>
decltype(auto) operator()(F&& f) const
{
auto fut = std::async(f);
return fut.get();
}
};891!
…wait, is that a good result?
It is, because it doesn’t change if more continuations are added. As an example…
auto f = initiate([]{ return 1; })
.then([](int x){ return x + 1; })
// ...20 identical continuations...
.then([](int x){ return x + 1; });…still produces 891
lines of assembly. This happens because decltype(f) is
a huge type containing all the types of the continuations - the compiler
is able to inline everything.
implementation
Let’s analyze the implementation, beginning with
initiate:
template <typename F>
auto initiate(F&& f)
{
return node{std::forward<F>(f)};
}The initiate function simply returns a node
storing the passed Callable. If you’re not used to C++17
features yet, you might think that node is a normal class:
it actually is a class template, and its template
arguments are being deduced thanks to class
template argument deduction. This is its perfect-forwarding deduction
guide:
template <typename FFwd>
node(FFwd&&) -> node<std::decay_t<FFwd>>;It basically means that when a node is constructed with
an object taken by FFwd&& forwarding
reference, the deduced class template arguments will be
std::decay_t<FFwd>. Let’s take a look at
node’s definition:
template <typename F>
struct node : F
{
template <typename FFwd>
node(FFwd&& f) : F{FWD(f)}
{
}
template <typename FThen>
auto then(FThen&& f_then);
template <typename Scheduler>
decltype(auto) execute(Scheduler&& s) &
{
return s(*this);
}
};The node class is a lightweight struct that
stores the Callable F via inheritance (to
enable the empty
base optimization). The node::execute member
function simply invokes *this through the passed scheduler
s (which might be something like a thread pool).
It is ref-qualified with & because some
schedulers might be non-blocking and we want to prevent temporaries from
being scheduled and immediately die before having a chance to finish
execution.
Also, FWD is just a macro that expands to:
#define FWD(...) ::std::forward<decltype(__VA_ARGS__)>(__VA_ARGS__)The final missing piece is node::then:
template <typename FThen>
auto then(FThen&& f_then)
{
return ::node{[
parent = std::move(*this),
f_then = FWD(f_then)
]() mutable -> decltype(auto)
{
return f_then(static_cast<F&>(parent)());
}};
}So short, yet so interesting:
::nodeis used instead ofnodeas class template argument deduction wouldn’t kick in otherwise (thanks T.C.!).A lambda expression is being passed to the new
node, which:Captures
std::move(*this)asparent. While this looks weird, it is completely fine to move*thisas long as it’s not going to be used anymore afterwards. What we’re doing here is crucial: we’re moving the current computation chain inside the newly created one without any allocation or type erasure: this means thatdecltype(*this)will be part of the type of the new continuation.Captures
f_thenby usingstd::forward. This is OK, but might not do what you expect whenf_thenis an lvalue reference: you might be interested in my previous “capturing perfectly-forwarded objects in lambdas” article.Is marked as
mutable. This is necessary as we may move the newly-creatednodeagain in subsequent computations, and moving doesn’t play nicely withconst.Has an explicit
decltype(auto)trailing return type, to allow references to be returned from user-definedCallableobjects. A lambda expressions defaults to-> autootherwise, which always makes a copy.Invokes the continuation
f_thenwith the result of invoking the move-captured*this. This means that all the continuations will be executed on the stack and their results will be passed down the computation chain until it’s over. Note that this could be improved by usingstd::invoketo truly support genericCallableobjects. Additionally, a scheduler-aware version ofthencould be provided, which might schedule thestatic_cast<F&>(parent)()call asynchronously instead of executing it synchronously, in order to avoid stack overflows - a possible drawback of that design choice could be introducing “deadlocks” in thread pools with a limited amount of threads (that will be waiting on each other).
So, what is the type of
f?
decltype(f) is huge, because there is no type erasure.
Let me show you an intentionally-produced compiler error from
the snippet with 22 .then continuations:

This is the end of the first part of “zero-allocation continuations”.
In the next one we’ll take a look at a possible implementation of
when_all, and experiment with thread pools.
I began experimenting with these kind of continuations a few months
ago - I was writing a library called orizzonte
that I abandoned to focus on other project (and because I was
frustrated by the lack of C++17 compiler compliance back then). I
made it public on GitHub today and might continue/rewrite it in the
future - regardless, you might find this
file interesting, where very generic (but slightly broken)
versions of .then and when_all reside.
Thanks for reading!