In part
1 and part
2 we have explored some techniques that allow us to build
simple future-like computation chains without type-erasure
or allocations. While our examples demonstrated the idea of nesting
computations by moving *this into a parent node
(resulting in “huge types”), they did not implement any
operation that could be executed in parallel.
Our goal is to have a new when_all node type at the end
of this article, which takes an arbitrary amount of
Callable objects, invokes them in
parallel, aggregates the results, and invokes an eventual
continuation afterwards. We’ll do this in a non-blocking
manner: the thread that completes the last
Callable will continue executing the rest of the
computation chain without blocking or context-switching.
How can we achieve this? Is our existing design good enough?
Unfortunately, the answer is no.
table of contents
flaws with the current design
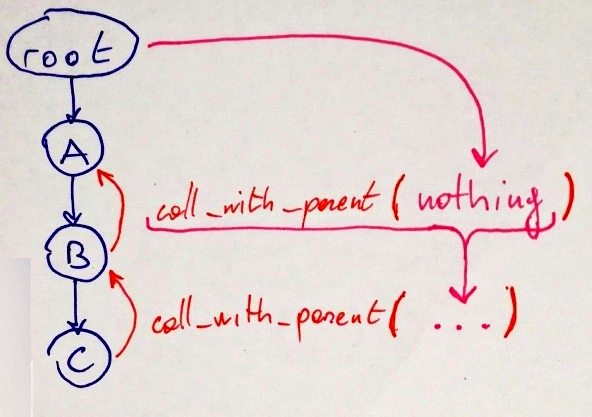
In our current design, the computation chain is executed bottom-to-top:
Every node only knows about its parent, but not about its children.
Every node expects to get a result when invoking the
.call_with_parent()member function. While this is enough to model linear chains, it’s not enough for a non-blocking fork/join model - it would mean that.call_with_parent()would have to block until all the parallel computations are completed so that a value can be returned.
Here’s a diagram of the current design:
Note that we could make when_all fit in our current
design, but it would need to block until all its computations are
completed (e.g. using a latch). Here’s an example
of how it would look:
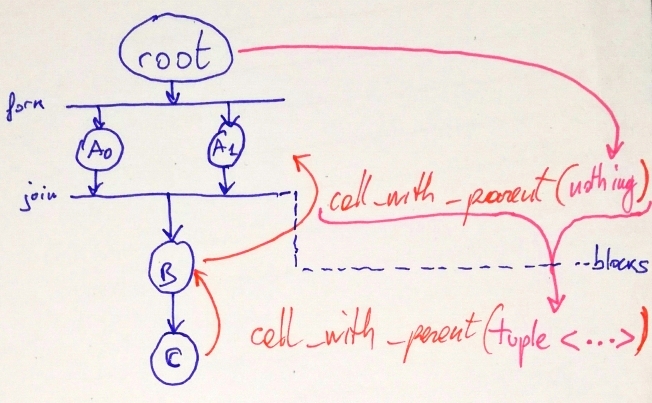
In order to allow when_all to have non-blocking
behavior, we have to almost literally turn our design upside-down: we’ll
begin at the root, recursively executing the children of the current
node.
When we are at the
root, we’ll simply execute its child.When executing a
node, we’ll invoke the stored computation and execute its child in the same thread, with the result of the function.When executing a
when_all, we’ll invoke every stored computation in parallel - the last one that finishes will execute the next child in the same thread.
We’ll have to solve two problems:
Finding the
root, while propagating the children.Going down the chain, executing everything in a non-blocking manner.
going up
Here’s a simple chain:
auto f = initiate([]{ return 1; })
.then([](int x){ return x + 1; })
.then([](int x){ return x + 1; });Remember that:
Every node stores and can access its parent, but has no knowledge about its children.
frepresents the final leaf of the chain.
How can we possibly find the
rootnode while still keeping track of all the children found along the way?
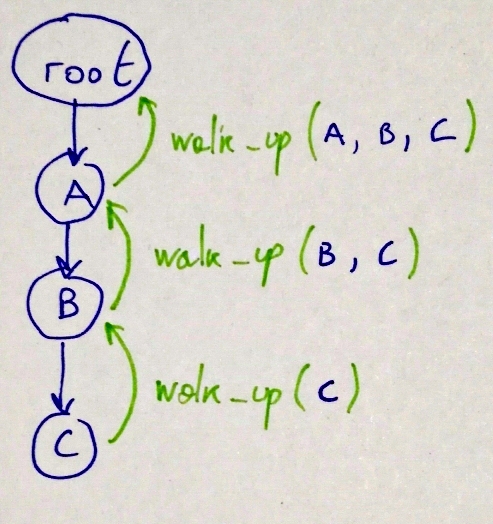
The answer is, of course, recursion. We’ll define a
walk_up member function that, when invoked, will invoke
itself recursively on the parent, passing the current node as an
argument. This will build a linear chain of nodes as a variadic set of
function arguments.
template <typename Scheduler, typename... Children>
void node</* ... */>::walk_up(Scheduler&& s, Children&... cs) &
{
this->as_parent().walk_up(s, *this, cs...);
}The first node on which walk_up will be invoked is the
final leaf. It will pass the scheduler and itself to its parent, which
will do the same recursively until the root is found. Upon
reaching the root, we’ll stop going up and begin going
down, having every node execute itself and its child.
Here’s an example diagram of walk_up invocations:
going down
The walk_up implementation for root will
start “going down”, by calling .execute on its child:
template <typename Scheduler, typename Child, typename... Children>
void root::walk_up(Scheduler&& s, Child& c, Children&... cs) &
{
c.execute(s, nothing{}, cs...);
}The semantics of .execute are as follows:
It always returns
void.It uses the scheduler only when appropriate.
For linear nodes
.executewill completely avoid using the scheduler, in order to chain everything on the same thread.For fork/join nodes with \(N\) computations it will execute one computation on the current thread, and schedule the remaining \(N - 1\).
It will call the current node’s stored computation(s) with the result value received from the parent.
If the current node is not a leaf, it will call
.executeon its child.
This is the signature of .execute:
// Leaf case:
template <typename Scheduler, typename Result>
void /* ... */::execute(Scheduler&&, Result&&) &;
// General case:
template <typename Scheduler, typename Result,
typename Child, typename... Children>
void /* ... */::execute(Scheduler&&, Result&&, Child&, Children&...) &As you can see, we always expect to get a scheduler and a result
(which could be nothing) from our parent. If the
current node is not a leaf, one or more children will be passed to
.execute from its parent.
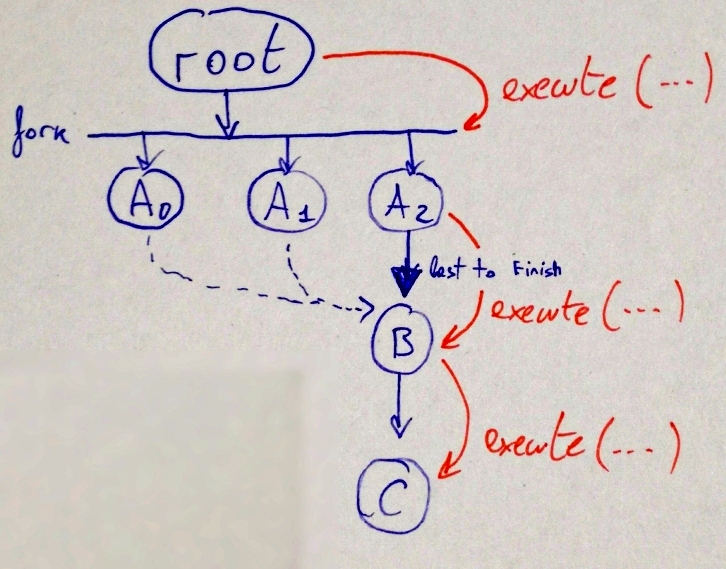
Here’s a diagram showing a simplified example of going down a linear chain:

You can see the benefit of this approach in the following diagram.
The scenario is as follows: after the root, there is a
when_all node with three computations (\(A_0\), \(A_1\), \(A_2\)). In the particular hypothetical
example run shown in the diagram, \(A_2\) is the last node to complete
execution. Since \(A_2\) knows that its
children are \(B\) and \(C\), it can invoke .execute on
\(B\) on the same thread, without
requiring blocking/synchronization.
implementation: linear
node
Let’s now take a look at how this new design is implemented in a
linear chain. Do not worry - I promise that I’ll show the implementation
for when_all in this article. We’ll begin with
boilerplate:
Every node will expose the
input_typeandoutput_typetype aliases which will be used to easily compute the final result value of a computation chain.Nodes will derive from a
child_of<Parent>base class, that reduces code repetition and simplifies CRTP usage.
struct root
{
// The `root` produces `nothing`.
using output_type = nothing;
// When we are at the `root`, we cannot go "up" the chain anymore.
// Therefore we being going "down".
template <typename Scheduler, typename Child, typename... Children>
void walk_up(Scheduler&& s, Child& c, Children&... cs) &
{
c.execute(s, nothing{}, cs...);
}
};template <typename Parent>
struct child_of : Parent
{
// The input type of a node is the output of its parent.
using input_type = typename Parent::output_type;
template <typename ParentFwd>
child_of(ParentFwd&& p);
auto& as_parent() noexcept;
{
return static_cast<Parent&>(*this);
}
};Here’s node’s interface:
template <typename Parent, typename F>
struct node : child_of<Parent>, F
{
using typename child_of<Parent>::input_type;
using output_type = result_of_ignoring_nothing_t<F&, input_type>;
template <typename ParentFwd, typename FFwd>
node(ParentFwd&&, FFwd&&);
template <typename FThen>
auto then(FThen&&) &&;
auto& as_f() noexcept;
template <typename Scheduler, typename Result>
void execute(Scheduler&&, Result&&) &;
template <typename Scheduler, typename Result,
typename Child, typename... Children>
void execute(Scheduler&&, Result&&, Child&, Children&...) &;
template <typename Scheduler, typename... Children>
void walk_up(Scheduler&&, Children&...) &;
template <typename Scheduler>
decltype(auto) wait_and_get(Scheduler&&) &&;
};It’s very similar to the implementation we had in the previous article, but there are a few things to note:
output_typeuses a weirdresult_of_ignoring_nothing_ttype alias - we’ll get to that in a bit. In short, it prevents passingnothingto another function to make the user interface more convenient.thenis now ref-qualified with&&- it’s a good idea to enforce that, as*thiswill be moved during its invocation. (Thanks to Андрей Давыдов for the suggestion.)We have
executeandwalk_up.
With our new design, wait_and_get remains unchanged. The
definition of node</* ... */>::then is however
greatly simplified, because we don’t need to propagate parents
anymore:
template <typename FThen>
auto node</* ... */>::then(FThen&& f_then) &&
{
return ::node{std::move(*this), FWD(f_then)};
}Let’s now take a look at .execute (general
case):
template <typename Scheduler, typename Result,
typename Child, typename... Children>
void node</* ... */>::execute(Scheduler&& s, Result&& r,
Child& c, Children&... cs) &
{
c.execute(s, as_f()(FWD(r)), cs...);
}Firstly, it executes the stored computation with the value received
from the parent node: as_f()(FWD(r)). It then invokes
.execute on the next child, propagating the scheduler, the
result of the computation, and the eventual rest of the children.
as_f()(FWD(r)) is a lie. The real code is
actually call_ignoring_nothing(as_f(), FWD(r)). The
call_ignoring_nothing(f, xs...) invokes f
passing all xs... that are not nothing as
arguments. Its implementation is explained in the appendix. The
previously encountered result_of_ignoring_nothing_t behaves
like std::invoke_result_t,
but uses call_ignoring_nothing instead of
std::invoke.
That’s basically it for linear nodes - you can find a complete example on wandbox.org or here on GitHub.
implementation:
when_all
Finally, we’re going to see some parallelism in action. The plan is
as follows: we’ll create a new type of node called when_all
that:
Stores \(N\) computations.
Schedules \(N - 1\) computations and executes the remaining one on the current thread.
Uses an internal
std::atomiccounter to keep track of pending computations. Whenever a computation is completed, the counter will be decremented and checked atomically: if it reached \(0\), it means that we’re the last computation to complete and that we need to move further down the chain.Stores a
std::tupleof the final results that will be filled by every computation.
This is what the interface looks like:
template <typename Parent, typename... Fs>
struct when_all : child_of<Parent>, Fs...
{
using typename child_of<Parent>::input_type;
using output_type =
std::tuple<result_of_ignoring_nothing_t<Fs&, input_type>...>;
movable_atomic<std::size_t> _left{sizeof...(Fs)};
output_type _out;
template <typename ParentFwd, typename... FFwds>
when_all(ParentFwd&&, FFwds&&...);
template <typename... FThens>
auto then(FThens&&...) &&;
template <typename Scheduler, typename... Children>
void walk_up(Scheduler&&, Children&... cs) &;
template <typename Scheduler, typename Result>
void execute(Scheduler&&, Result&&) &;
template <typename Scheduler, typename Result,
typename Child, typename... Children>
void execute(Scheduler&&, Result&&, Child&, Children&...) &;
template <typename Scheduler>
decltype(auto) wait_and_get(Scheduler&&) &&;
};
template <typename ParentFwd, typename... FFwds>
when_all(ParentFwd&&, FFwds&&...)
-> when_all<std::decay_t<ParentFwd>, std::decay_t<FFwds>...>;It is almost identical to a linear node, but has a few
important differences:
The constructor and deduction guide accept \(N\)
Callableobjects. We could statically assert that \(N > 1\).The struct contains the
_leftand_outmembers: these represent the shared state between all parallel computations. The_leftatomic, as previously said, is used to figure out what computation finished last. The_outdata member is used to store computations’ result values.- Note that these cannot be local variables in
.execute, as it is completely non-blocking. We previously got away with a statelessnodeclass because we had no scheduling and a single execution path: in that particular case we could just call.executeon the next child with the result value of the computation, executed in the same thread.
- Note that these cannot be local variables in
You might also have noticed that .then is now a
variadic function template. It will now either produce a
node or a when_all depending on the amount of
passed functions:
template <typename... FThens>
auto /* ... */::then(FThens&&... f_thens) &&
{
static_assert(sizeof...(FThens) > 0);
if constexpr(sizeof...(FThens) == 1)
{
return ::node{std::move(*this), FWD(f_thens)...};
}
else
{
return ::when_all{std::move(*this), FWD(f_thens)...};
}
}The initiate function has also become more interesting:
it will instantiate a schedule, which is a new auxiliary
node type which simply schedules the next child (instead of running
it on the main thread). This allows more fine-grained control in
the future, as the user might or might not want to schedule a
computation chain depending on the context. Every invocation of
initiate will either return a node or a
when_all:
template <typename... Fs>
auto initiate(Fs&&... fs)
{
return schedule{root{}}.then(FWD(fs)...);
}Before diving into when_all::execute, let’s take a look
at a usage example:
auto f = initiate([]{ std::puts("A0"); return 1; },
[]{ std::puts("A1"); return 2; })
.then([](auto t)
{
auto [a0, a1] = t;
return a0 + a1;
});
assert(std::move(f).wait_and_get(world_s_best_thread_pool{}) == 3);In the above code snippet, initiate will produce a
when_all node with two computations. In practice, you will
see "A0" and "A1" being printed in an
arbitrary order. When the last of the two computations is completed, the
.then continuation will be invoked with a tuple containing
\((1, 2)\). We then use structured
bindings to unpack the tuple and return the final result, which
should always be \(3\). As always,
wait_and_get guarantees to block until the whole chain is
completed thanks to a latch.
Let’s now look at the most interesting part:
when_all::execute. We’ll only analyze the general
case, as the leaf case is pretty much the same.
template <typename Scheduler, typename Result,
typename Child, typename... Children>
void execute(Scheduler&& s, Result&& r, Child& c, Children&... cs) &
{
enumerate_args([&](auto i, auto t)
{
auto do_computation = [&]
{
using type = typename decltype(t)::type;
std::get<decltype(i){}>(_out) =
call_ignoring_nothing(static_cast<type&>(*this), r);
if(_left.fetch_sub(1) == 1)
{
c.execute(s, std::move(_out), cs...);
}
};
if constexpr(i == sizeof...(Fs) - 1)
{
do_computation();
}
else
{
s([&]{ do_computation(); });
}
}, type_wrapper_v<Fs>...);
}There’s a lot going on here. Firstly, let’s look at
enumerate_args:
enumerate_args([&](auto i, auto t)
{
// ...
}, type_wrapper_v<Fs>...)This is a simple metaprogramming utility that, given an arbitrary
amount of compile-time values, executes an user-defined action passing
the index as the first argument and the value as the
second argument. You can think about it as a compile-time version of Python’s
enumerate(...) function. Its implementation is
explained in the appendix.
We’re passing type_wrapper_v<Fs>... to
enumerate_args. As the name suggests,
type_wrapper is a simple compile-time value-like wrapper
over a type - if you’re familiar with Boost.Hana this should seem
natural to you. Here’s its implementation:
template <typename T>
struct type_wrapper { using type = T; };
template <typename T>
inline constexpr type_wrapper<T> type_wrapper_v{};
template <typename T>
using unwrap = typename std::decay_t<T>::type;Our lambda will be invoked multiple times, like this:
lambda(std::integral_constant<int, 0>{}, type_wrapper_v<f0>)lambda(std::integral_constant<int, 1>{}, type_wrapper_v<f1>)…
lambda(std::integral_constant<int, N>{}, type_wrapper_v<fN>)
Inside the lambda passed to enumerate_args we define
another lambda: do_computation. It contains the
instructions to execute for the current computation and will be invoked
either with or without the scheduler:
auto do_computation = [&]
{
// Get the current computation's type out of the type wrapper.
using type = typename decltype(t)::type;
// Invoke the computation and assign its result to the `i`-th
// element of the `_out` tuple.
std::get<decltype(i){}>(_out) =
call_ignoring_nothing(static_cast<type&>(*this), r);
// If this was the last computation to finish, continue further
// down the computation chain.
if(_left.fetch_sub(1) == 1)
{
c.execute(s, std::move(_out), cs...);
}
};The _left.fetch_sub(1) == 1 makes sure that the
decrement and check is performed atomically. We’re checking equality
against 1 and not 0 as std::atomic<T>::fetch_sub
returns the value of the atomic prior to the decrement.
Finally, we branch at compile-time to check whether or not we should schedule the current computation:
if constexpr(i == sizeof...(Fs) - 1)
{
// If this is the last computation, do not schedule it.
do_computation();
}
else
{
// Otherwise, schedule it.
s([&]{ do_computation(); });
}This prevents “wasting” the thread running
when_all</* ... */>::execute.
That’s it! You can find a complete example on wandbox.org or here on GitHub.
Note that the current implementation produces invalid assembly with
g++ due to a compiler bug. You can find
more information here and it is trivial to work
around the issue. Also, clang++ produces some nonsensical
warnings related to deduction guides that I suppressed using
-Wno-undefined-internal.
appendix:
call_ignoring_nothing
Given a FunctionObject f and a set of
arguments xs..., this utility invokes f with
all xs... that are not nothing. Here are some
examples of what call_ignoring_nothing does:
call_ignoring_nothing(f, 0, 1, 2)\(\to\)f(0, 1, 2)call_ignoring_nothing(f, 0, nothing, 2)\(\to\)f(0, 2)call_ignoring_nothing(f, nothing)\(\to\)f()call_ignoring_nothing(f, 0, nothing, nothing, 1, nothing, 2, nothing)\(\to\)f(0, 1, 2)
Its implementation is recursive. The base case is when there are no
arguments: f is invoked immediately.
template <typename F>
decltype(auto) call_ignoring_nothing(F&& f)
{
return returning_nothing_instead_of_void(FWD(f));
}Here’s the recursive case:
template <typename F, typename T, typename... Ts>
decltype(auto) call_ignoring_nothing(F&& f, T&& x, Ts&&... xs)
{
return call_ignoring_nothing([&](auto&&... ys) -> decltype(auto)
{
if constexpr(std::is_same_v<std::decay_t<T>, nothing>)
{
return FWD(f)(FWD(ys)...);
}
else
{
return FWD(f)(FWD(x), FWD(ys)...);
}
}, FWD(xs)...);
}Basically, it matches the first argument x and a
possibly empty set of remaining arguments xs.... It
recurses over call_ignoring_nothing, binding x
to f if it’s not nothing, otherwise completely
ignoring it.
Using call_ignoring_nothing allows users to write…
initiate([]{ }).then([]{ });…instead of:
initiate([](nothing){ }).then([](nothing){ });appendix:
enumerate_args
This one is quite simple, but useful. The interface
enumerate_args function invokes
enumerate_args_impl, passing an
std::index_sequence<0, 1, ..., N>, where
N is the number of arguments:
template <typename F, typename... Ts>
void enumerate_args(F&& f, Ts&&... xs)
{
enumerate_args_impl(std::index_sequence_for<Ts...>{}, FWD(f), FWD(xs)...);
}Inside enumerate_args_impl I use a fold
expression that expands both Is... and
xs... in lockstep to produce “pairs” of “index +
argument”:
template <typename F, typename... Ts, std::size_t... Is>
void enumerate_args_impl(std::index_sequence<Is...>, F&& f, Ts&&... xs)
{
(f(std::integral_constant<std::size_t, Is>{}, FWD(xs)), ...);
}